
Nowadays, applications often operate on such a large amount of data, that usually one application instance is not enough to handle all traffic, making it necessary to split all of it into many application instances. The system should get a job to do, like sending data to one of instances of services and return result data.
This article is for java developers who want to start developing applications in microservice architecture using Kafka, or plan to join a project where it is used.
This study analyzes the pros and cons on Apache Kafka microservice application architecture, and includes a practical part where we download and install Apache Kafka, send example messages via console, create the simplest demo application and some practical use case.

Event-driven architecture
Event-driven architecture is a design pattern in which many applications can asynchronously communicate with each other using a message broker by publishing and subscribing to events (event streaming).
Event streaming is real-time data capturing from event sources like cloud services, databases, devices and sensors, storing these event streams durably for later processing, and reacting to the event streams in real-time and retrospectively. The event is routed to a different destination as needed.
Event streaming can be used in many cases, including:
- To track fleets of vehicles and delivery cars logistics.
- To analyze sensor data in internet of things.
- To process payments and financial operations in real-time.
- To monitor and analyze patients' health status in hospitals, as well as to react immediately for emergencies.
- To collect and immediately react to the customer’s interactions and orders
Event-driven applications can be created in many programming languages because event-driven is a programming case, not a programming language.
There are a many event-driven applications but the most popular are Apache Kafka and Rabbit MQ. Of course, RabbitMQ has a lot of advantages over Apache Kafka, like transactional data type and smart broker not constrains for data size but Apache Kafka advantages over RabbitMQ are performance, smart consumer and publish/subscribe topology.
RabbitMQ is used only for simple cases, while Apache Kafka can be used for massive data/high throughput cases.
In this article I will show you an example using Java and Apache Kafka.
Apache Kafka – Introduction
Apache Kafka is written in Scala open-source software platform founded on a distributed streaming process, that works in a publish-subscribe based messaging system. It is fast, it is scalable and fault tolerant.
In most of commercial applications, loads of data must be processed, so in some cases we need to use the microservices to divide an application into smaller ones. Those will communicate with each other through the message queuing system. Kafka Messaging Queuing System is responsible for transferring data asynchronously from one application to another, so that the app can focus on data. Kafka resolve the lethargic trouble of data communication between a sender and a receiver. It can be used in many instances such as monitoring data, log aggregation and stream processing.
Apache Kafka has a lot of advantages like Reliability, Scalability, Durability and Performance.
Kafka is a distributed system consisting of clients and servers that communicate with each other using the TCP network protocol.
Kafka servers can be deployed on:
- Bare-metal hardware
- Virtual machines
- Containers
- Cloud
Clients allow users to write microservices that create, read, and process streams pararelly. They are available in many languages such as:
- Java
- Python
- C++
- Go
Two types of messaging patterns offered:
- point to point
- publish-subscribe
Point to point
In a point-to-point system many users can consume the messages in the queue, but a particular message can be consumed by only one person, and after consumption the message is deleted from the queue.
Point to point messaging is used, among others:
- Order processing system – each order is processed by one order processor, but many order processors function at the same time;
- Ticket solving system – each ticket is processed by only one processor, but multiple tickets can be processed parallelly by multiple ticket processors.

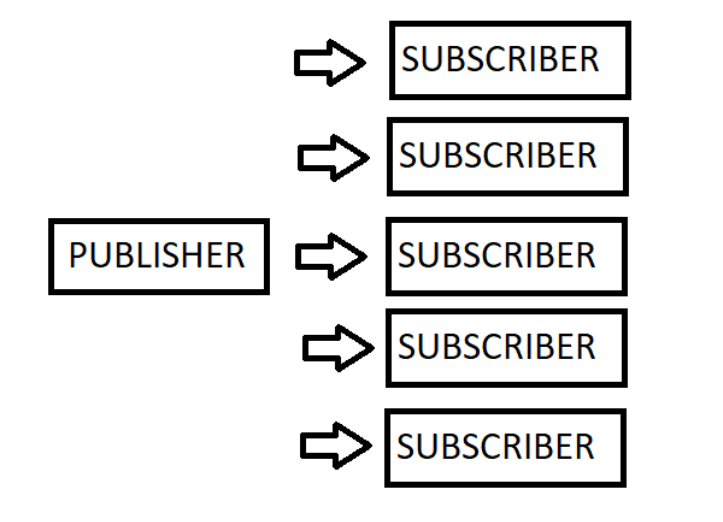
Publish-subscribe
Publish-Subscribe Processing System, where each order will be processed by one Order Processor, but Multiple Order Processors can work as well at the same time.
In the publish-subscribe messaging pattern messages are stored in a topic.
Unlike the point-to-point system consumers can subscribe to many topics and consume all the data topic data.
Apache Kafka cons
Microservice architecture has a lot of advantages but also involve a numer of disadvantages such as:
- If even one of the microservices does not work, often the entire application has to stop.
- Higher complexity – Complexity can by challenging for people that are not used to working witch microservices. They must learn something new and change their way of thinking.
- It can be more expensive than a monolith application.
- Increase network traffic – due to sending great amount of data between microservices, the network traffic will be increased, as well as the response time.
- Harder to test and debug – If some use case requires usage of various microservice, we must open and run each one, and in some cases, this is impossible.
- Limited reuse of code – if we have some utils which are used in numerous microservice, we must have them in all projects or pack it to some external library.
- Microservices change business model.
- Apache Kafka processes a lot of data; it is obvious that we need an internet connection with both high bandwidth and a very low latency.
If we have such a model: microservice “A” calls microservice “B” and microservice “B” calls microservice “C”, after that microservice “C” get some data from database and microservice “C” returning it to microservice “B”. Finally, microservice “B” returning data to microservice “A”.
If we come across this scenario: microservice “B” is down, so the microservice “A” cannot send data to the microservice “B” and of course data to microservice “C” will not send either. Microservice “C” cannot send data to “B” and the microservice “A” never reads topic from “C”.
In the second case, the microservice “C” is down, so after sending topic from microservice “A” to microservice “B”, it cannot send data to microservice “C” - and of course it cannot get data from the database.
If every microservice is independent and ninety percent time online and ten percent offline, the example systems only 72,9 percent of the time. But in monolith application, we still have a ninety percent working time.
Of course, in the case of the microservice “A” that communicates with microservice “B” (and reverse) only in some cases, and communicates with microservice “C” with rest of the cases, the system availability will be higher.
When using Apache Kafka is a bad idea?
If we add up all the disadvantages of Apache Kafka, we can find many applications where using Kafka is almost forbidden.
First case is when application works in real time and need a very low latency, Kafka is very fast but not working in real time, in some cases broker can slow down.
The second reason is that Kafka is not designed to create peer-to-peer application. It is designed to connect between multiple services, but not for millions of them, so if you create application of this type, please do not use Kafka directly to communicate users to each other.
Top mistakes when you using Apache Kafka.
- Using default values in consumers and producers, this which is not secure.
- We do not secure data to avoid damage by processing messages only once.
- Using only one partition per topic, when we should set more than one partition per cluster and try to replicate these partitions to avoid data loss by deleting physical files.
- Using only one broker instance if the broker gets broken or some connection between producer-broker or broker-consumer, we lose our data.
Testing Apache Kafka applications
You must design an application to be fault tolerant and handle failures properly. It should be also able to check if the error of one service will not put down the whole application.
In the multiservice application we have multiple components that can cause many failures.
Reasons of the failures are as follows:
- Bad deployments - we are using old version of one of the microservice.
- Datacenter failure.
- Poor or too complicated architecture.
- Critical exceptions in the code.
- Communication with not reliable services or network.
Before you put your application into production, you have to do a lot of testing - unit testing, of course, but you also have to perform a lot of manual testing as well.
During the tests we must focus on data flow, so it’s good to do this:
- Create pretest conditions like creating entity in the database, setting the status of the object.
- Make action that will be tested.
- Check if topic is created properly and all data is correctly set.
- Check if the topic has been correctly read by the client application.
- Check if producer application not throw us error after sending the message.
In the application with multiple microservices you must check if all data was delivered correctly. Verify if there is no data loss problem the easiest way is to do fit test data validations. They will check and confirm that no message has been missed by either the publisher or the subscriber in the last few days.
After these tests we must do a performance test to check if the application is working fine without any glitches.
Kafka security
In a few applications, any microservice can read any topic for any service, but in some applications we need to forbid this for some reason. For example, a topic that contains very sensitive data, such as personal data or highly protected company information, which should not be accessible to unauthorised persons.
The problem is solved by Kafka security.
There are three Kafka security components:
- SSL Authentication that verifies producers and consumers before give access to a secured Kafka cluster.
- ACL Authorization – Access control list that determine what client ha right to write or read a topic.
- Data encryption – data can be encrypted by encryption algorithm like TLS.
We'll go over Apache Kafka and its functions in greater detail in the following article, so be sure to read it. You've gotten a lot of information this time, which I hope you'll find useful. See you again soon!


