
In recent years, one of the most popular technologies has been speech recognition. This is due to the huge variety of uses and needs. This technology has improved considerably in recent years, but it does not always produce excellent results. In this article, I will focus on the Speech-to-text API comparison. It will also show how to easily calculate the accuracy of speech-to-text processing technology
What is Speech-to-text?
Speech-to-text technology uses software to identify and process spoken language. The process of synthesizing speech consists of several steps, the two main steps being natural language processing and digital signal processing. Speech-to-text technology, also known as speech recognition technology, converts spoken words or audio content into text. This is accomplished through the use of applications, APIs, tools, and other software tools.
Thus, speech-to-text APIs are simple interfaces that perform speech recognition to transcribe voice to text. They are based on machine learning and artificial intelligence to detect patterns in sound waves.
How does speech-to-text technology work?
Speech-to-text technology works by listening to audio and converting it to text. The software uses language algorithms to sort audio signals from spoken words and translate those signals into text using characters. The words spoken by a person produce a series of vibrations. Speech-to-text technology picks up these vibrations and converts them into a digital language using an analog-to-digital converter. This converter takes the sounds from the audio file and measures the waves in detail and filters them to distinguish between the corresponding sounds. The sounds are then broken down into thousands of a second and matched with phonemes (the sound units that distinguish one word from another in a given language). In the next step, the phenomena are passed through the network using a mathematical model that compares them with known words and sentences. Then the text is presented based on the most probable version of the sound.
Why use Speech-to-text?
Speech-to-text technology is highly functional and often the only option for users with disabilities who do not use the keyboard. This technology can make it very easy for deaf or hard-of-hearing students to make lecture notes. The lecturer's speech can be automatically converted into text. This reduces the difficulties and increases productivity.
Another use of speech-to-text technology is to make it easier to type large text or to write messages while driving. You don't have to enter every word by hand. You can use an API that will generate a written text.
Speech-to-text technology can also be used for voice commands. Many innovations in speech recognition technology have been introduced by the automotive industry. Companies like Apple and Google, have changed the way voice activation is used in vehicles. Apple Carplay and Android Auto allow you to control many functions of the car by voice.
How to measure the accuracy of Speech-to-text
In the process of recognizing speech and converting it to text, some words may be omitted, added or mistranslated. Accuracy is a very important aspect to consider when choosing a speech-to-text API.
The main measure of accuracy for speech-to-text technology is the word error rate (WER). WER is the number of errors divisible by the total number of words.
To calculate WER, sum the substitutions, insertions, and deletions that occur in the recognized word sequence, then divide that number by the total number of words originally spoken.
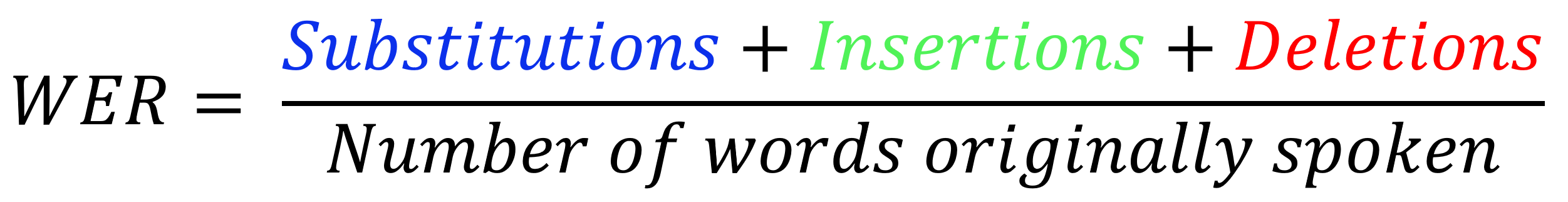
- A substitution is when a word is replaced
- An insertion is when a word is added that wasn’t said
- A deletion is when a word is omitted from the transcript
Here is an example that shows incorrectly identified words compared to human spoken words:
Today is a beautiful day
Today a beautiful the days
The deleted word "is", the added word "the" and the replaced the word "day" with "days".
The number of words originally spoken is 5.
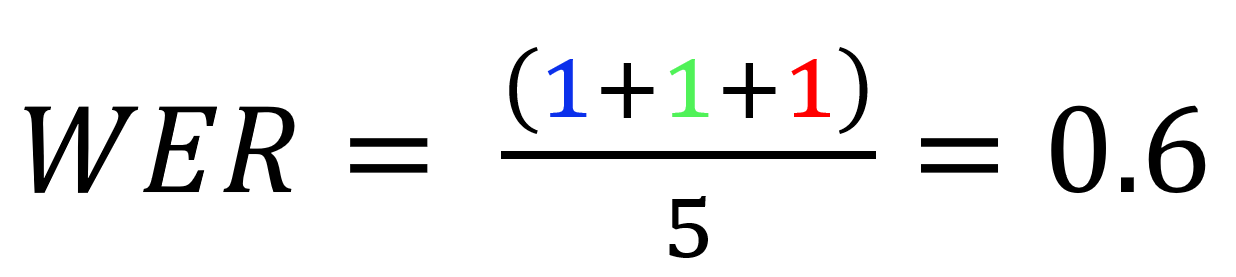
The word accuracy (Wacc) is calculated using the formula:
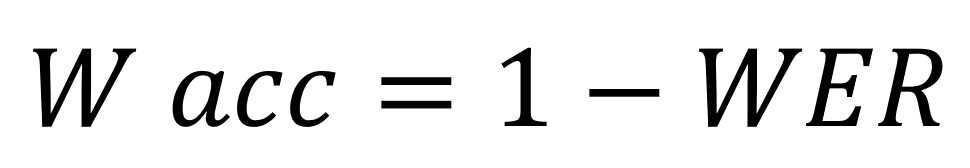
For the example above, it is:
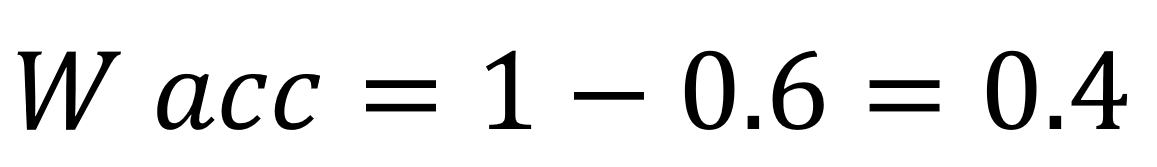
Comparison and results
There are many speech-to-text conversion technologies available out there. In this article I would like to focus on comparing services from Google (Google Cloud Speech API), Microsoft (Microsoft Azure Bing Speech API) and Amazon (Amazon Transcribe).
The services will be compared in terms of transcription speed and accuracy. Converting Speech-to-text will be from audio files.
To test the services, I created a test audio database that contains 14 audiobook fragments in .wav format and frequency 16000hz. The audio recordings are in English and the original text for each audio file is also stored in the database.
The next step was the implantation of three Speech-to-text conversion tools from Google, Microsoft and Amazon. For each of them, a method has been implemented to calculate the time (milliseconds) needed for speech-to-text conversions for each audio file.
In the next step, I proceeded to count the accuracy of the transcription. The accuracy of the speech-to-text conversion is counted using the Word Error rate.
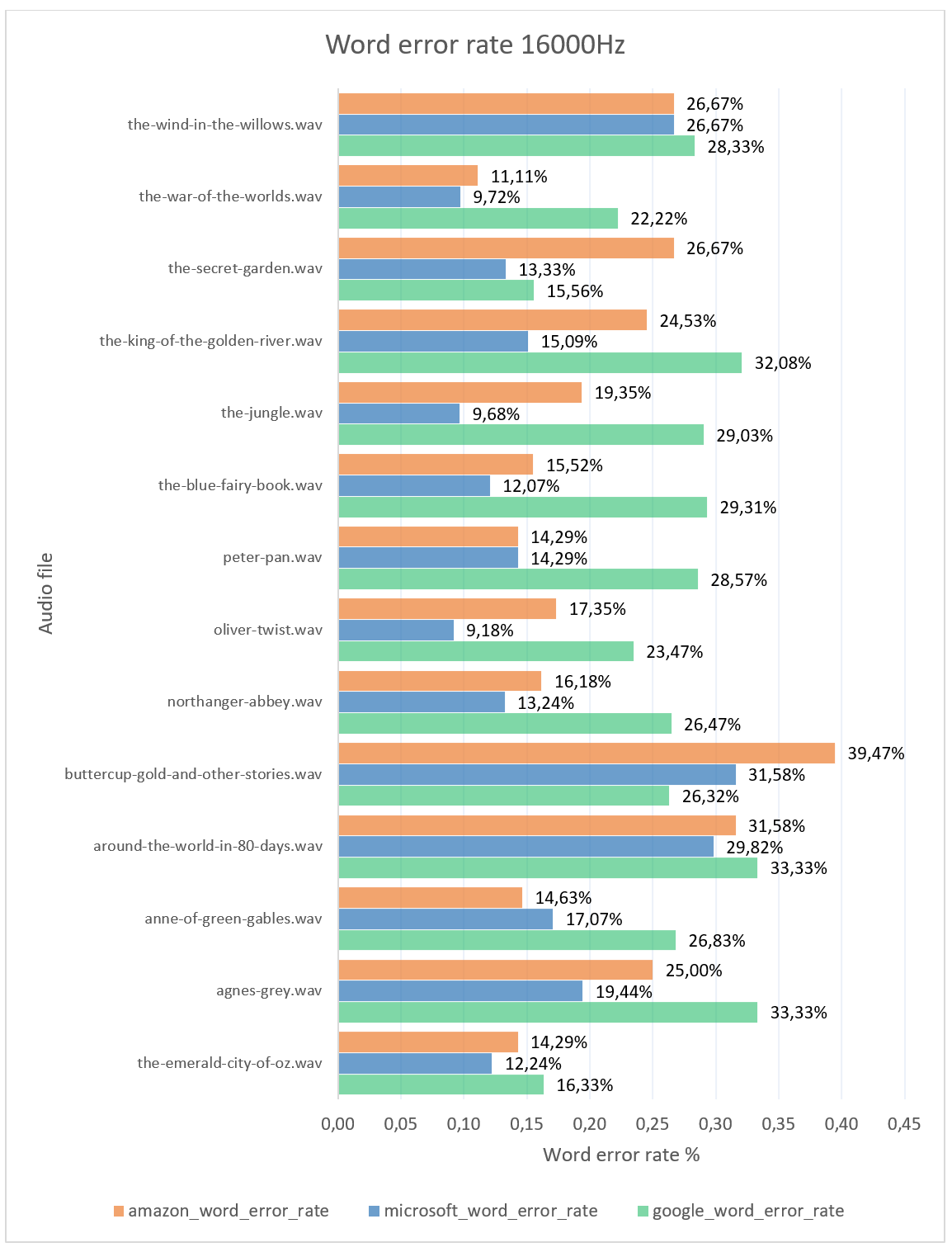
From the chart above, it can be read that the Microsoft API usually has the smallest word error rate. The average word error rate for Google is 28.45%, for Amazon 20.89% and for Microsoft 16.49%. This means that in the case of transcribing audio files, the API from Microsoft has the least error, hence the best accuracy of the speech-to-text conversion.
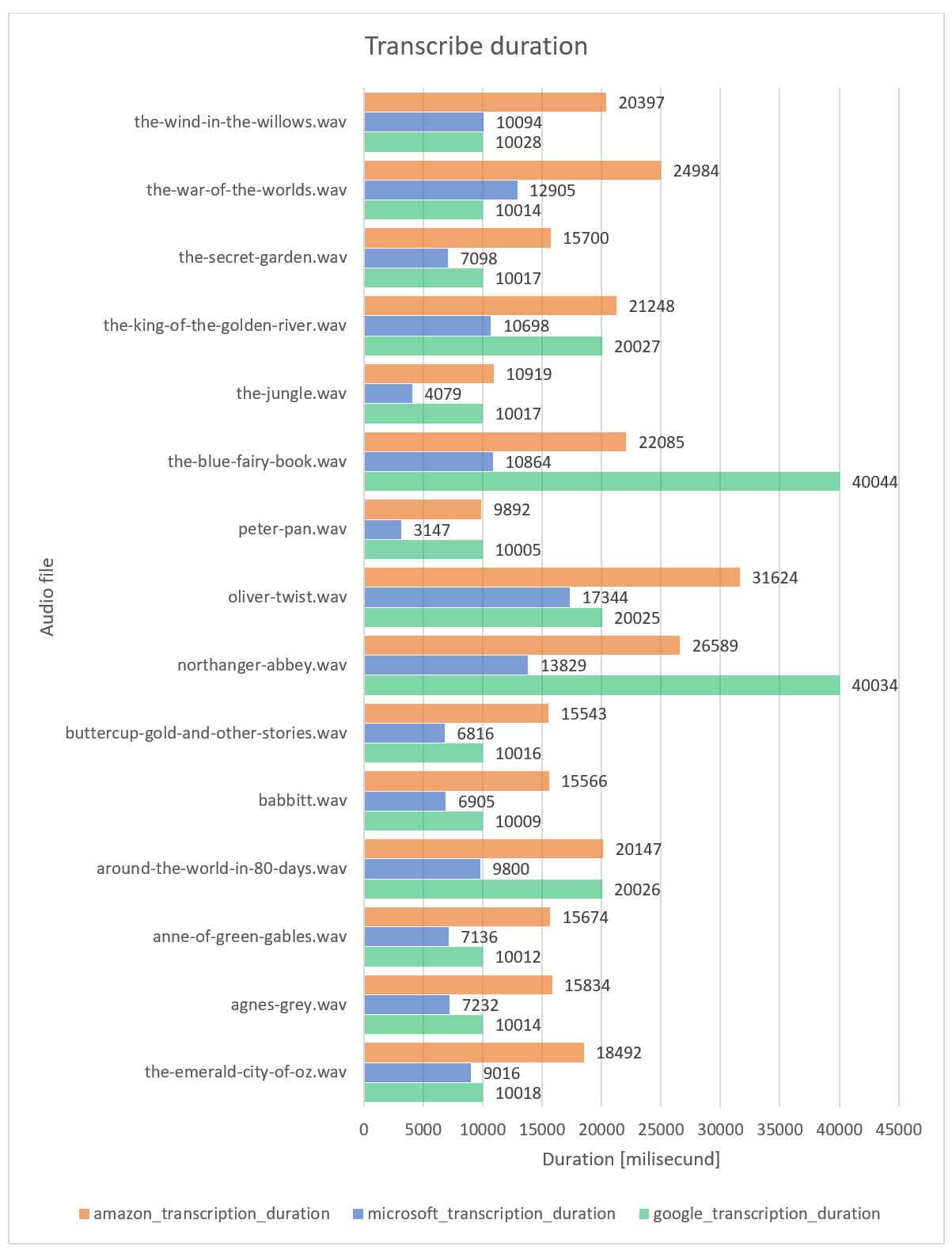
From the chart above, it can be seen that in most cases the shortest conversion time was achieved by API from Microsoft. Amazon's API was ranked second. Once again the API from Google turned out to be the worst.
Conclusion
In this article, we analyzed the key features of various APIs that perform speech-to-text tasks. Thanks to these modern technologies, communication becomes much more natural and productive. The most accurate speech-to-text conversion tool in the case of transcribing from audio files is the API from Microsoft, with an average word error rate of 16.49%. Amazon's API is in second place, where the average word error rate was 20.89%. Finally, the Google API was ranked with the highest average error of 28.45%. A similar situation occurs with the speed of speech-to-text conversion. In this case, too, the Microsoft API proved to be the best (fastest conversion). Amazon's API came in second place. With the worst conversion times overall, the Google API ended up being the worst. This means that, in terms of speed and conversion accuracy, the Microsoft API will be the best choice for converting speech-to-text from audio files.


