It all starts, when you find yourself in one of the most exciting points of your web development journey: a moment of shifting your focus from styles, esthetics and grid systems to logic, frameworks and writing JavaScript code.
At this very moment you begin to see that when it comes to JS, it’s much more than a few simple jQuery tricks and visual effects. You see a big picture of yourself creating web applications — not just mere web pages.
While you put more and more effort into creating JS code, you start to think about interactivity, your subsystems and logic. Things begin to work — and at last, you feel the life in your apps. A whole new, exciting world appears in front of you. And with that, a lot of new great problems.

But you’re not discouraged — new ideas are popping out constantly, you write more and more code. Various techniques from that certain blog post are being tested, assorted approaches to solving problems are being tinkered with.
Then, you start to feel a small itch.
Your filescript.js grows. An hour ago it
had 200 lines of code, now it exceeds 500 lines. “Hey” — you think— “it’s not a big
deal”. You’ve read about clean and maintainable code — and to achieve that, you begin separating your
logic into files, blocks and components. Things start looking beautiful again. Everything is neatly
catalogued like in a meticulously organized library. You feel good because various files
are named properly and placed in a certain directory. Code becomes modular and more maintainable.
Out of nowhere, you start feeling another itch coming — but the cause is not clear yet.
Web applications are rarely linear in their behaviour. In fact, many actions in any web app are supposed to happen suddenly (sometimes even unexpectedly or spontaneously).
Apps need to properly respond to network events, user interactions, timing mechanisms and various deferred actions. Out of nowhere, ugly monsters named “asynchronicity” and “race condition” are knocking to your doors.

You need to marry your handsome modular structure with an ugly bride — asynchronous code. And then the itch becomes obvious. A difficult questions begin to rise: where in the hell should I put this piece of code?
You might have your app beautifully
divided into building blocks. Navigational and content components can be placed neatly in proper
directories, smaller helper script files could contain repetitive code performing mundane tasks. Everything
can be managed by a single entry codeapp.js file, where it all starts. Neat.
But your goal is to invoke asynchronous code in one part of the app, process it and send it to another part.
Should the asynchronous code be placed in the UI component? Or in the main file? Which building block of your app should be responsible for handling the reaction? Which one for processing? What about error handling? You test various approaches in your mind — but your uneasy feeling won’t go away — you are aware of the fact that if you’d like to expand and scale this code, it will get tougher and tougher. Itch didn’t go away yet. You need to find some ideal, versatile solution.
Relax, it isn’t something wrong with you. In fact, the more structured your thinking is, this kind of itch will be more intense.
You start to read about dealing with
this problem and seek for ready-to-use solutions. In the first moment, you read about advantages of promises
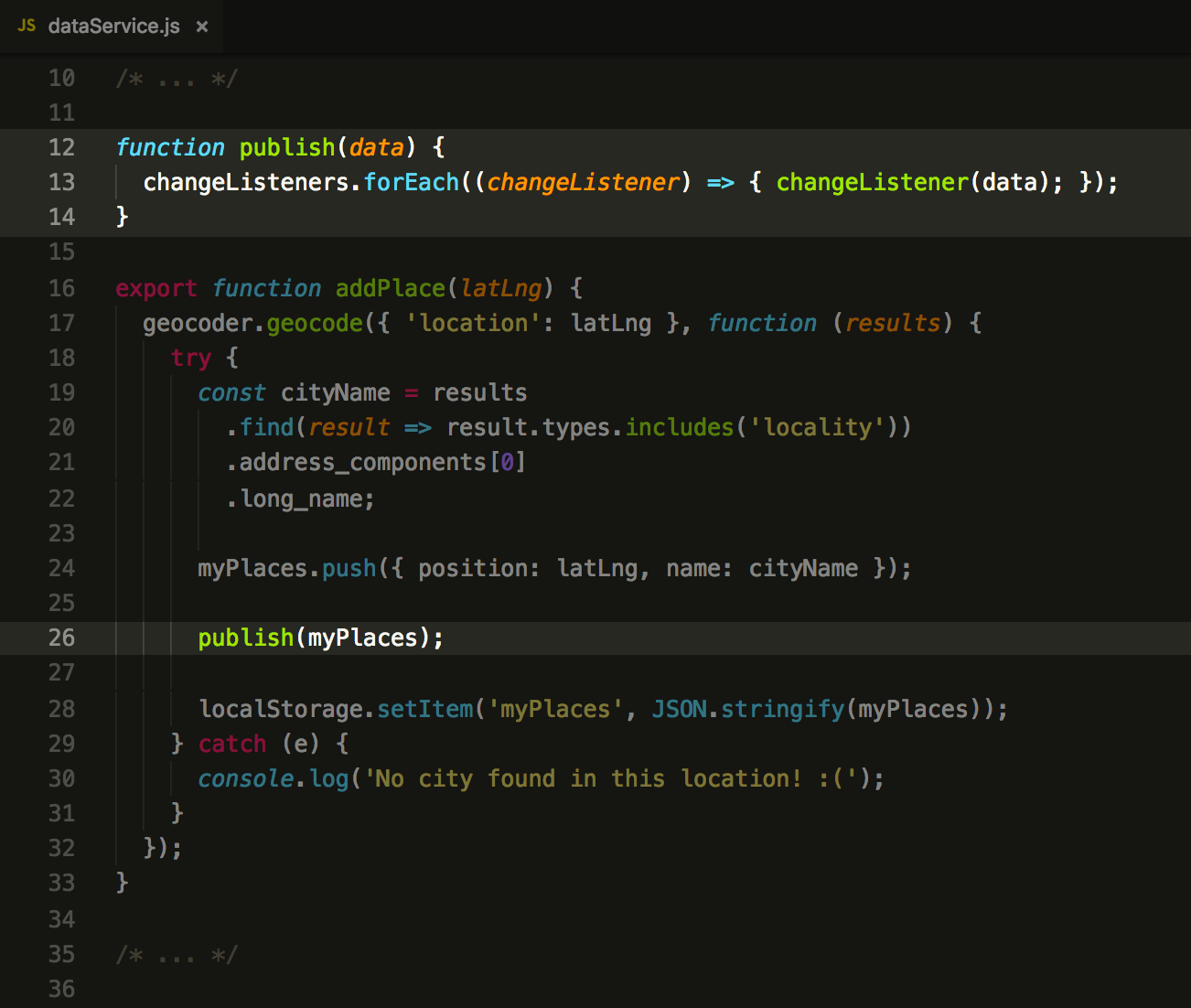
over callbacks. Next hour, you find yourself trying to comprehend what is RxJS (and why some random guy on
the internet says that it is the only legitimate salvation for the web-developing mankind). After some more
reading, you try to understand, why one blogger wrote that redux without redux-thunkdoesn’t make sense, but another one thinks the same
about redux-saga.
At the end of the day, your aching head is full of various buzzwords. Your mind explodes from a vast number of possible approaches. So, why there is so many of them? Shouldn’t it be simple? And do people really love arguing on the internet, instead of developing one good pattern?
It’s because this subject isn’t trivial.
Regardless of framework used, proper arrangement of asynchronous code is not and never will be obviously straightforward. There is no single, all-purpose, established solution. It heavily depends on requirements, environment, desired results and many other factors.
Also, this story isn’t going to provide with the über-all-problems-solving solution. But it will hopefully let you think of an asynchronous code a little easier — because it all based on a pretty basic principle.
Common parts
From a certain point of view,
programming languages are not complicated in their structure. After all, they’re just dumb calculator-like
machines that are capable of storing values in various boxes and changing its flow due to some ifs or function calls. As
an imperative and slightly object-oriented language, JavaScript is not much of a different species
here.
It means that under the hood, all cosmic asynchronous contraptions from various points of the galaxy (either it is redux-saga, RxJS, observables or zillion of other mutants) must rely on the same basic principles. Their magic is not so magic — it must be built on well-known foundations, nothing new is invented on the lower level here.
Why is this fact so important? Let us think of an example.
Let’s do (and break) something
Consider a simple application, a really simple one. For instance, a small app for marking our favourite places on a map. Nothing fancy there: just a map view on the right and simple sidebar on the left. Clicking on a map should save a new marker on a map.
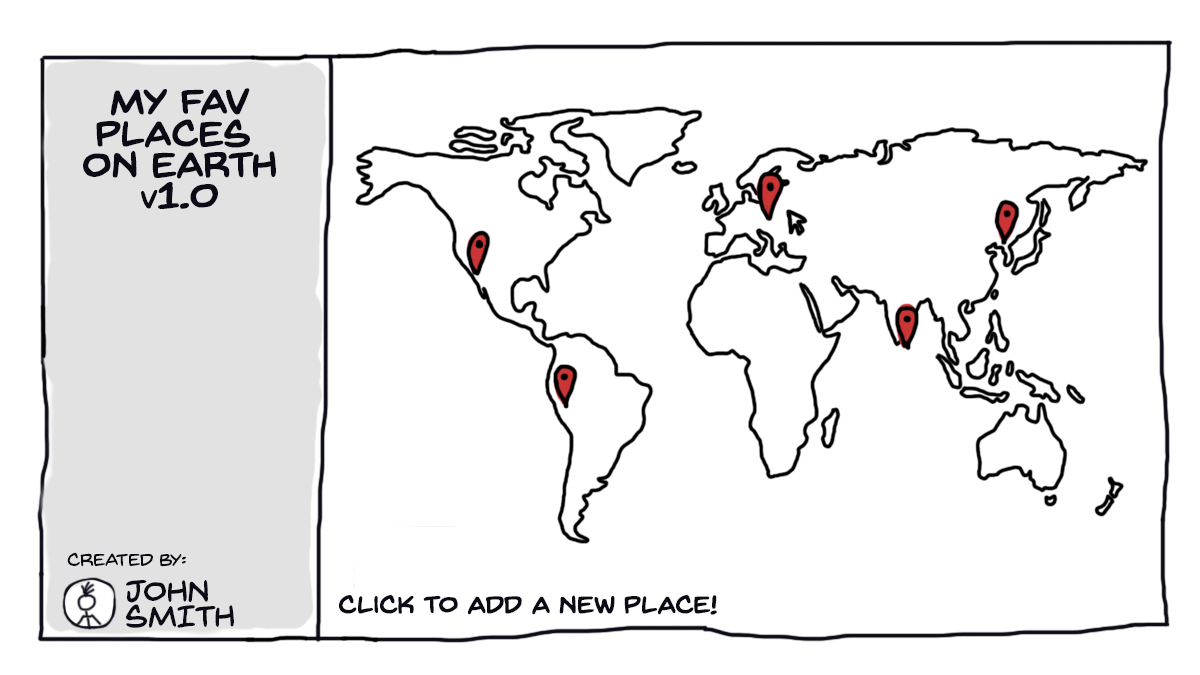
Of course, we’re a little ambitious and we’re going to make additional feature: we want it to remember the list of places using local storage.
Now, based on that description, we can draw some basic action flow chart for our app:
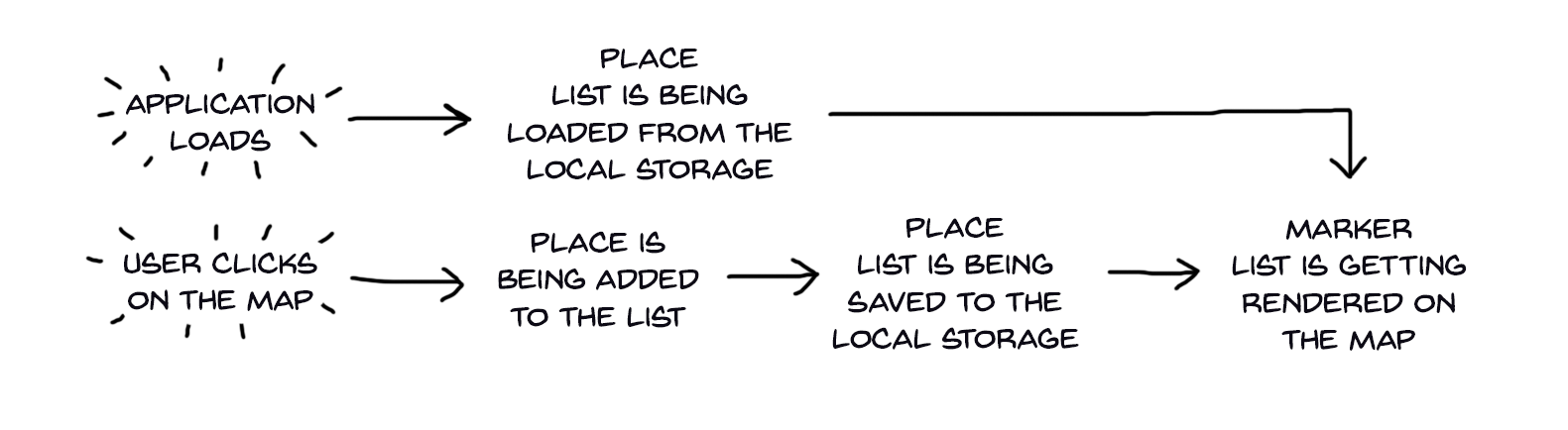
As you can see, it isn’t going to be complicated.
For brevity, following examples are going to be written without using any framework nor UI library — only vanilla JavaScript is involved. Also, we’re going to use small part of Google Maps API — if you want to create similar app yourself, you should register your API key on https://cloud.google.com/maps-platform/#get-started.
Okay, let’s get down to coding and create a quick prototype:
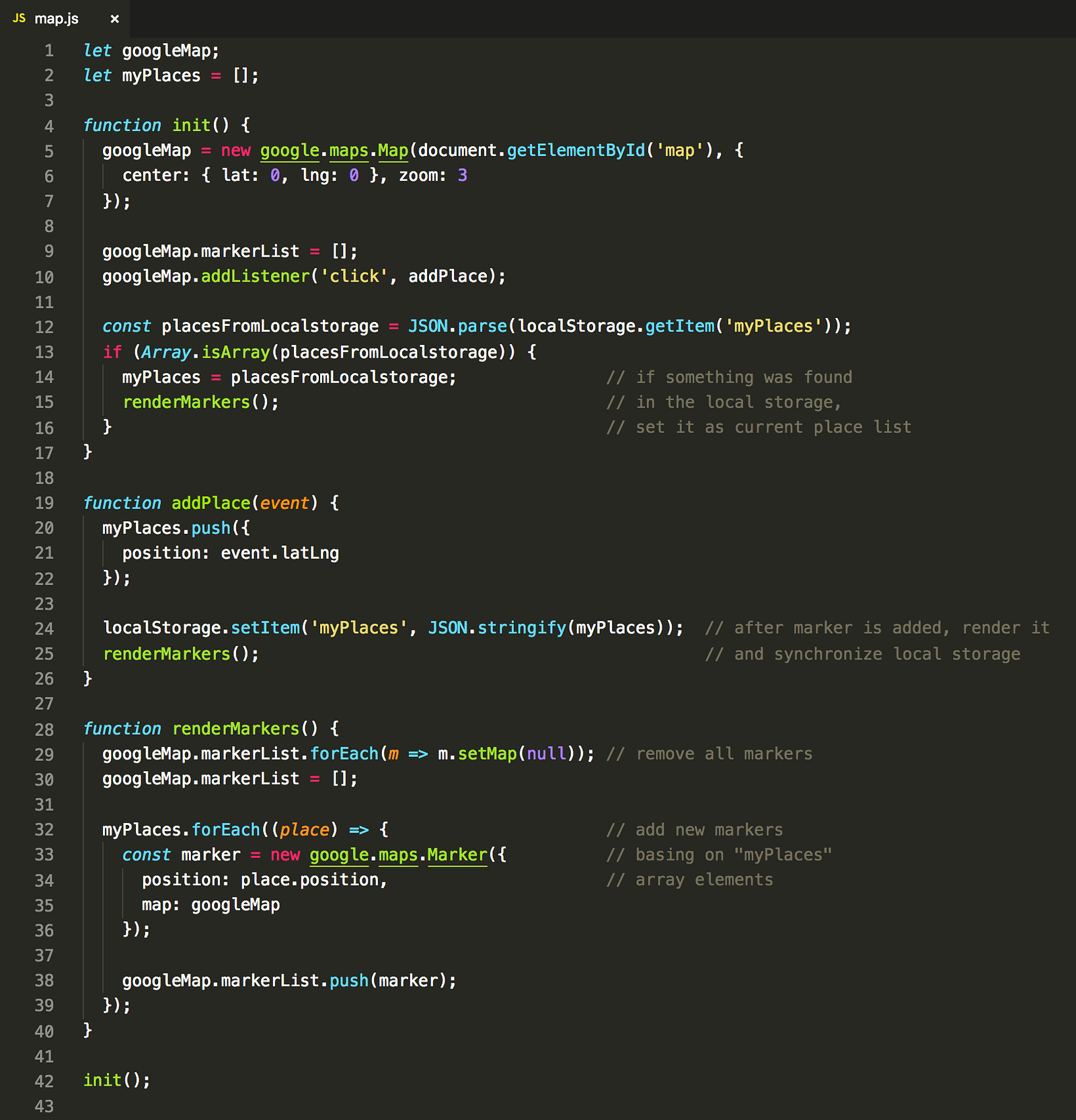
Let’s quickly analyze this one:
-
init()the function initializes the map element using Google Maps API, sets up the map click action and then tries to load markers from the localStorage. -
addPlace()handles the map click — then adds a new place to the list and invokes marker rendering. -
renderMarkers()iterates through the places in the array and after clearing the map puts the markers on it.
Let’s put aside some imperfections here (monkey patching, no error handling etc.) — it will serve good enough as the prototype. Neat. Let’s build some markup for that:
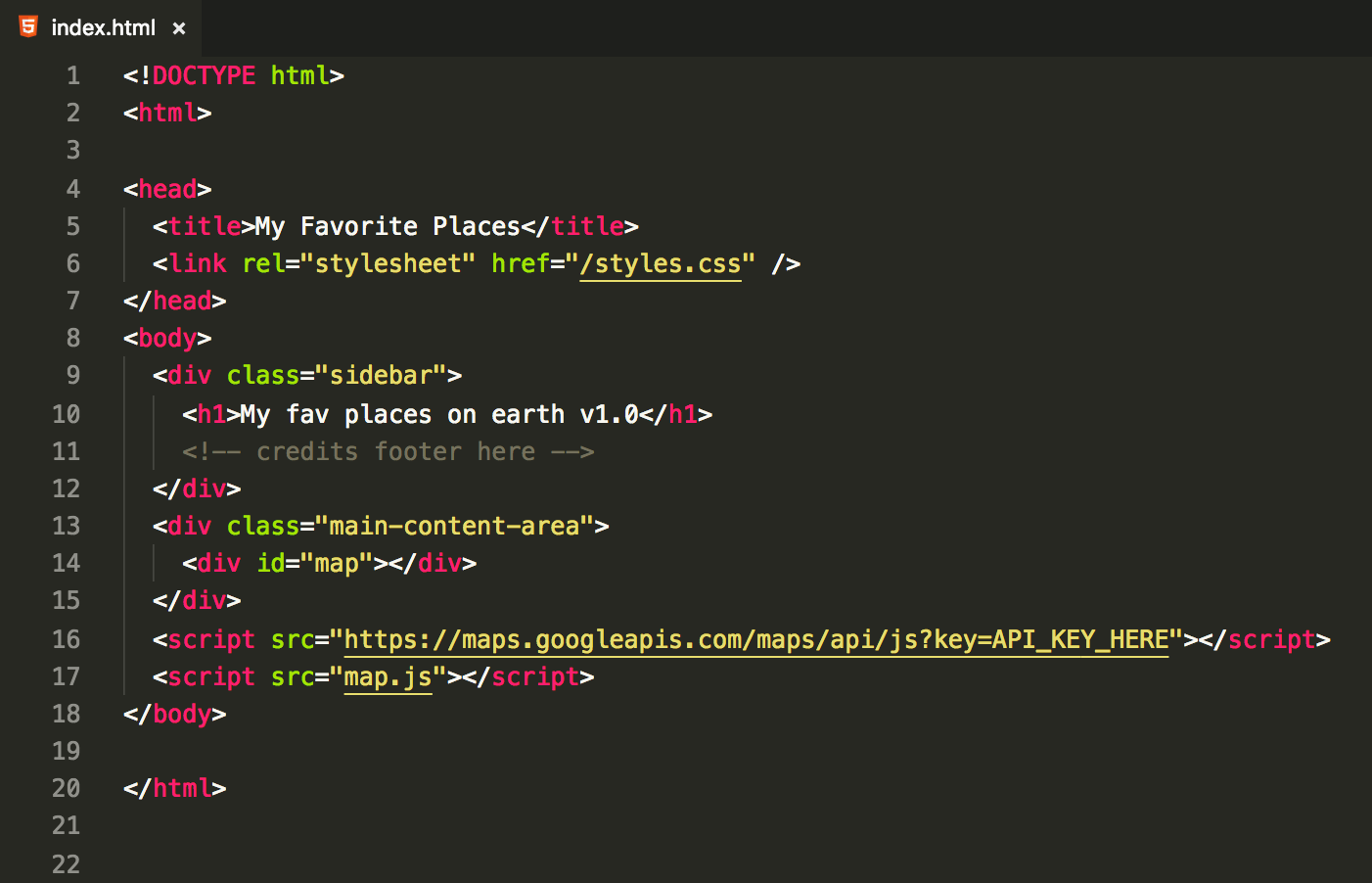
Assuming that we have some styles attached (we won’t cover it here since it’s not relevant), believe me, or not — it actually does its job:
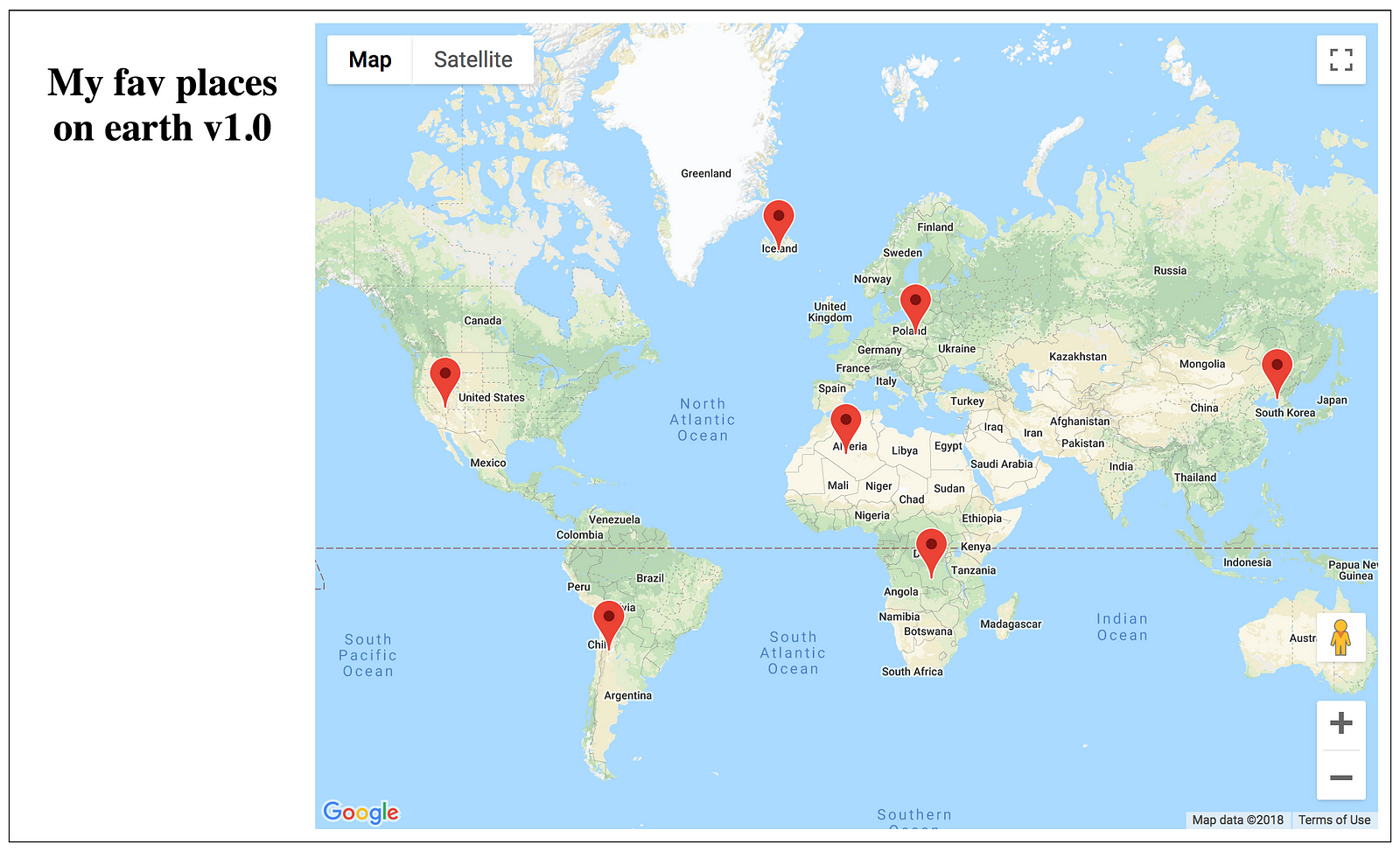
Despite being ugly, it works. But is not scalable. Uh-oh.
First of all, we’re mixing responsibilities here. If you’ve heard about SOLID principles, you should already know that we’re already breaking the first of them: Single Responsibility Principle. In our example — despite its simplicity — one code file is taking care of both handling the user actions and dealing with data and its synchronization. It shouldn’t. Why? “Hey, it works, right?” — you might say. Well, it does, but it is hardly maintainable in terms of next functionalities.
Let me convince you in another way. Imagine that we are going to extend our app and add new features there:
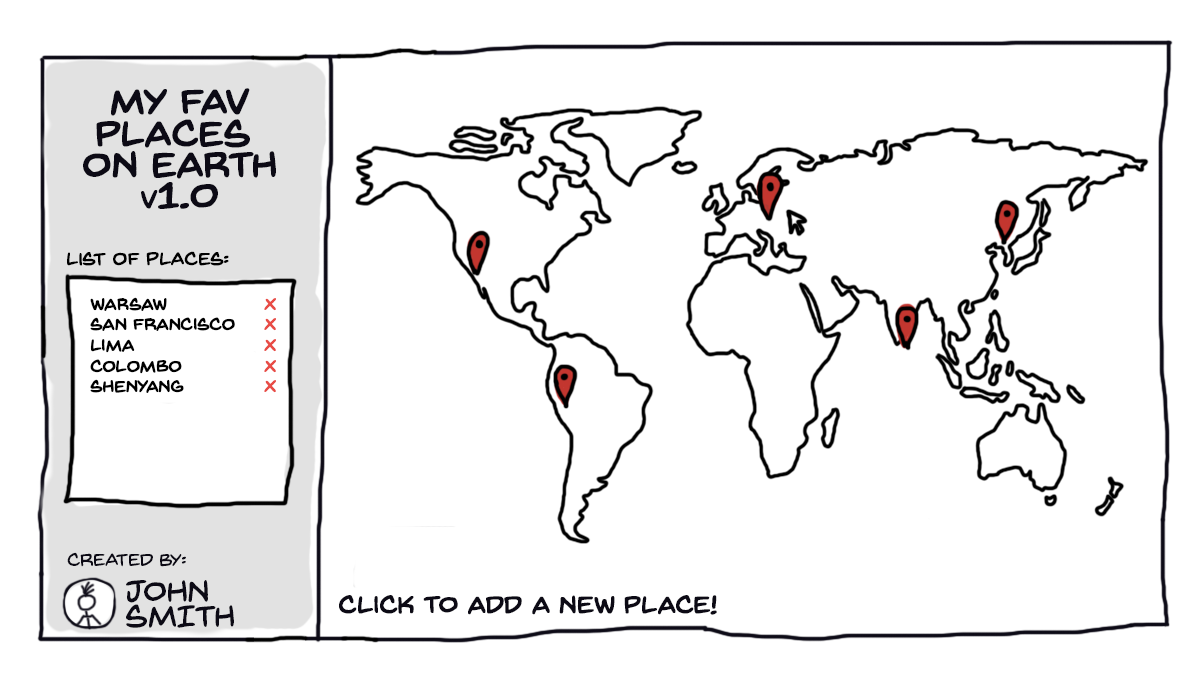
First of all, we want to have a list of marked places in the sidebar. Second, we want to look up city names by Google API — and this is where asynchronous mechanisms are introduced.
Okay, so our new flowchart will have the following shape:
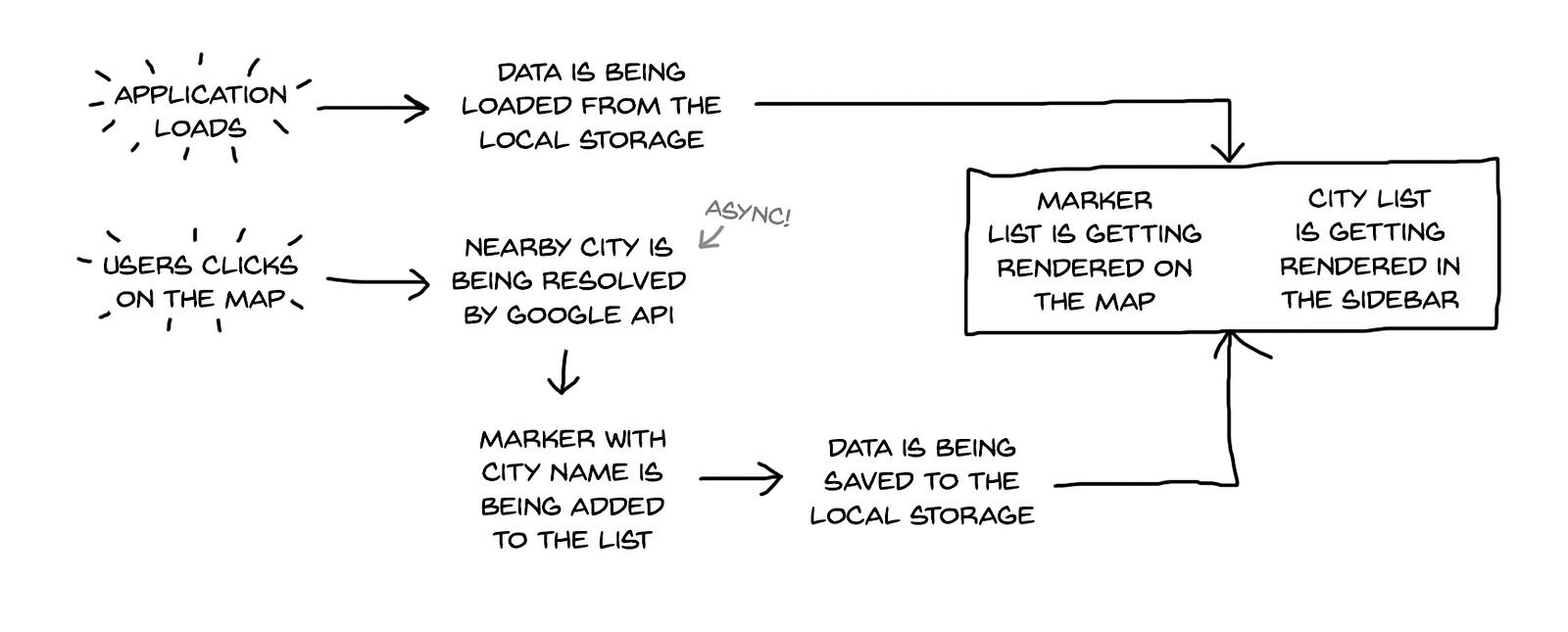
There is a certain characteristic of getting the city name from the Google API: it’s not instant. It needs to call proper service in Google’s JavaScript library, and it will take some time for the response to come back. It will cause a little complication — but surely an educational one.
Let’s go back to the UI and try to notice one apparent thing. There are two supposedly separate interface areas: the sidebar and the main content area. We definitely should not write one big piece of code that handles both. The reason is obvious — what if in the future we will have four components? Or six? Or 100? We need to have our code divided into chunks — this way, we will have two separate JavaScript files. One for the sidebar, second for the map. And the question is — which one should keep the array with the places?
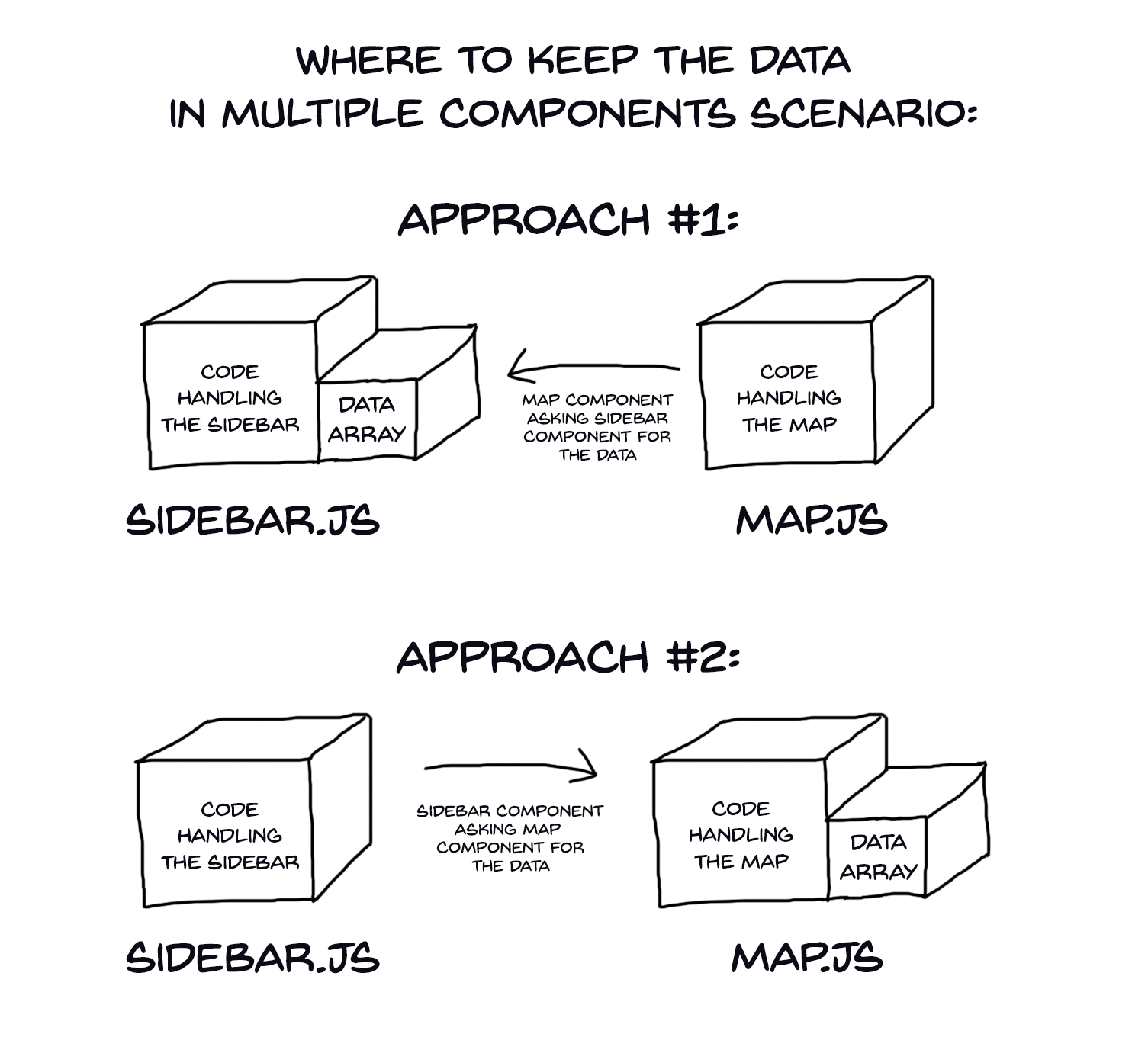
Which approach is correct here? Number one or number two? Well, the answer is neither one. Remember the single responsibility principle? In order to stay clean and modular (and cool) we should somehow separate concerns and hold our data logic somewhere else. Behold:
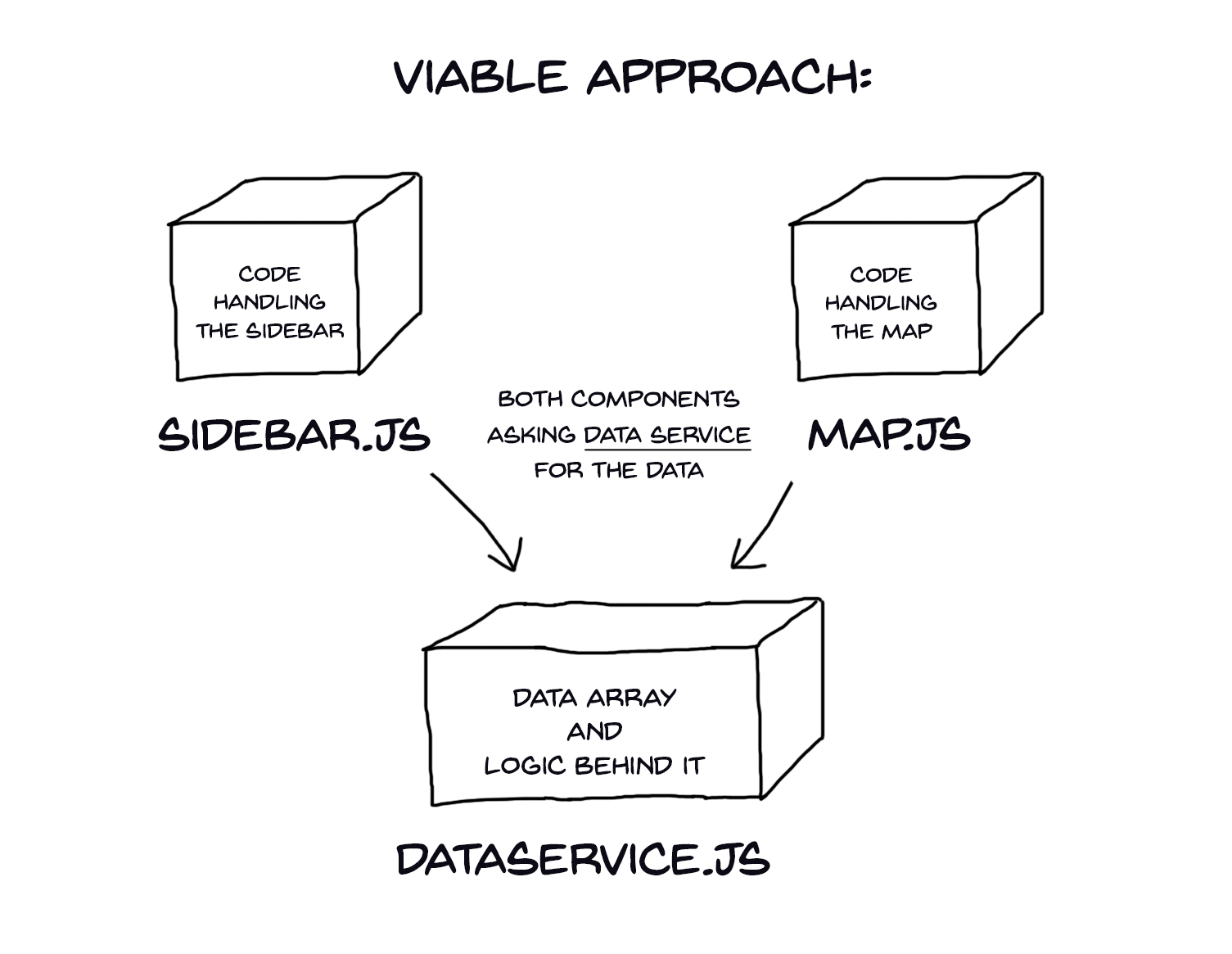
A holy grail of code separation: we can move the storage and logic into another code file, which will centrally deal with the data. This file —the service — will be responsible for those concerns and mechanisms like synchronization with local storage. Contrary, components will only serve as interface parts. SOLID as it should be. Let’s try to introduce this pattern:
Service code:
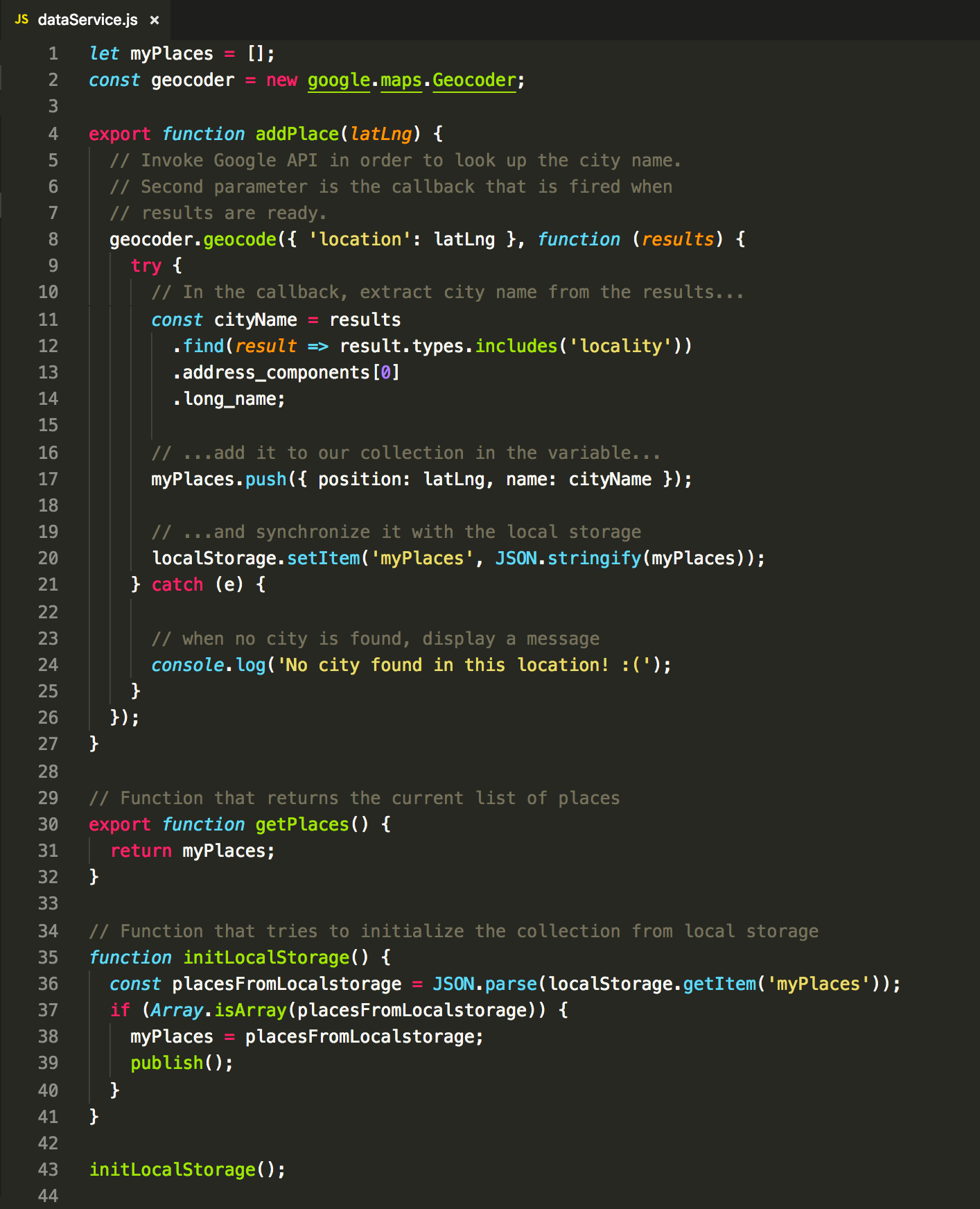
Map component code:
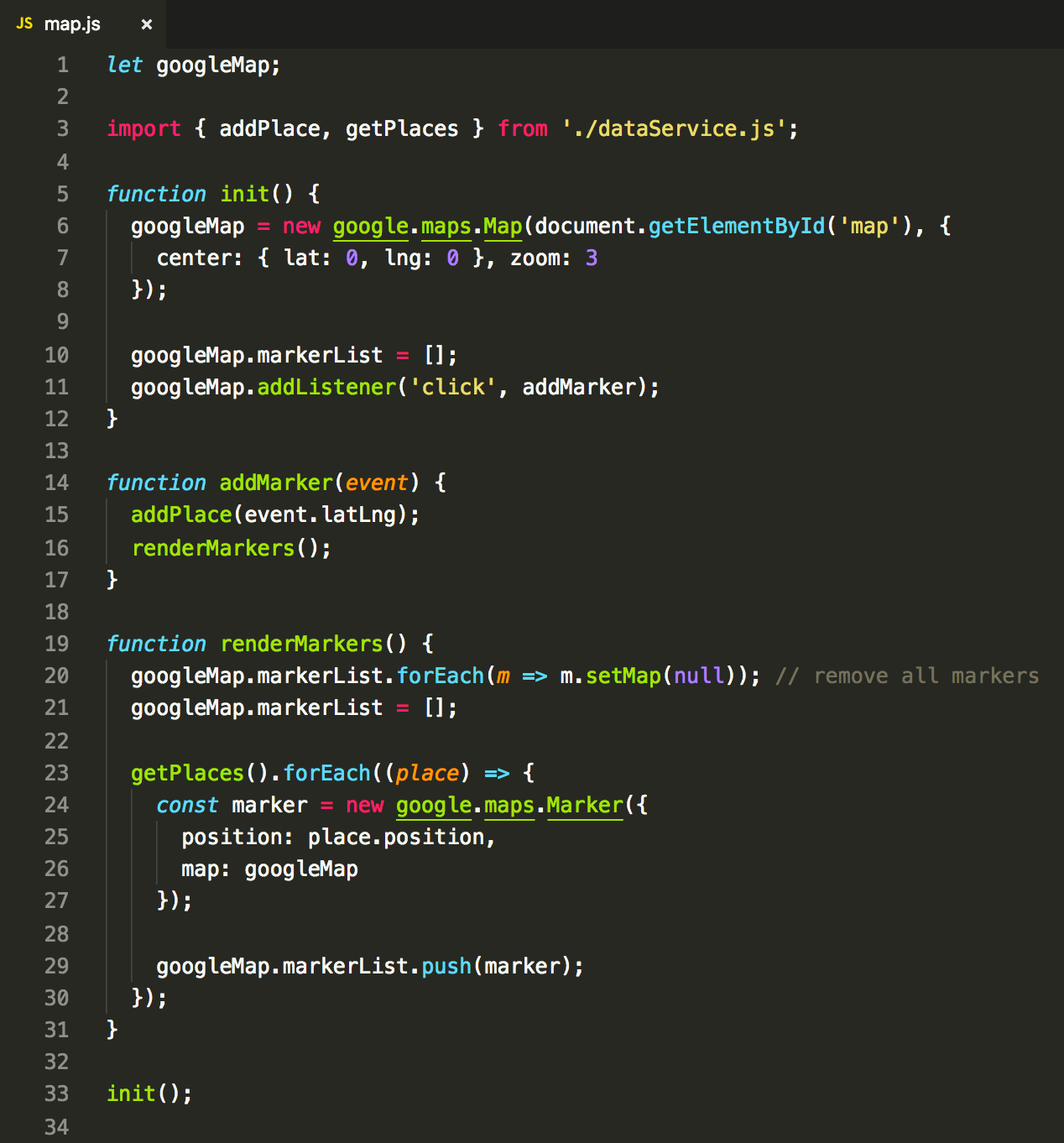
Sidebar component code:
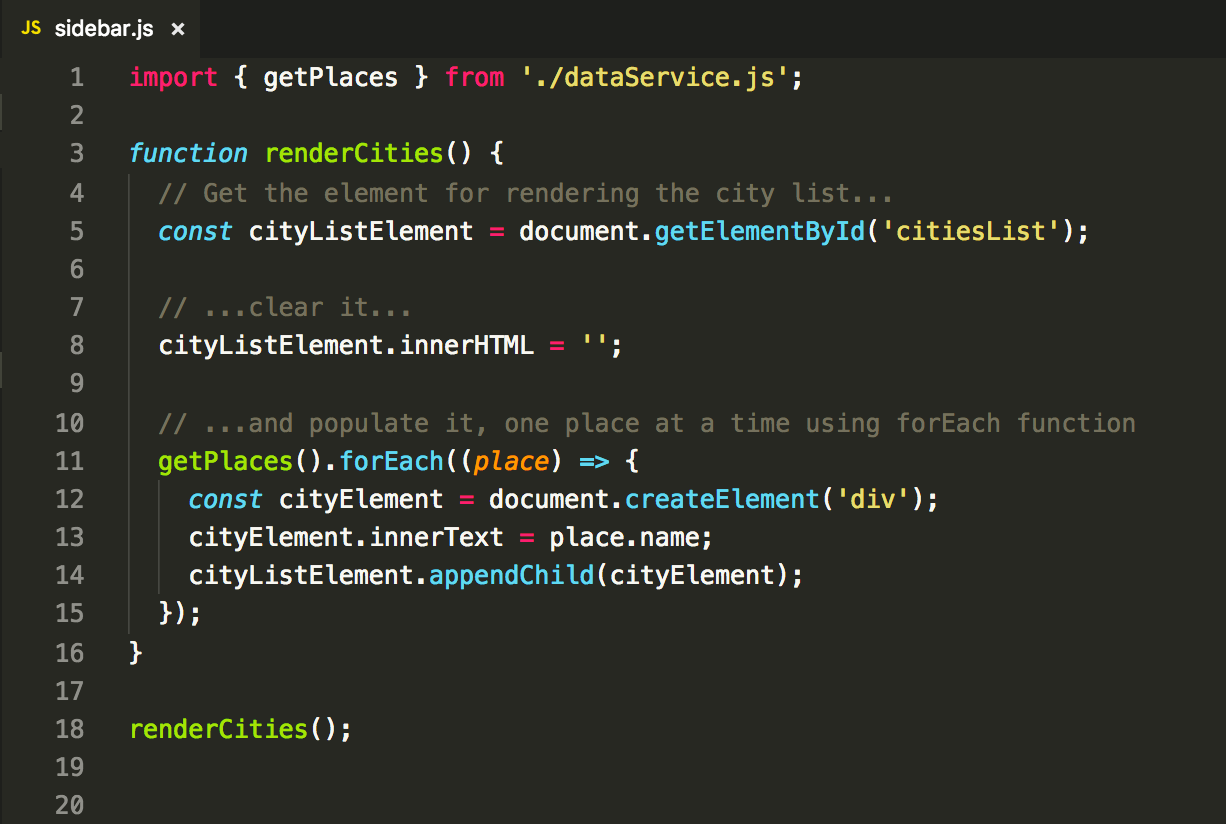
Well, the great part of the itch is gone. The code is neatly organized in proper drawers again. But before we start feeling good again, let’s run this one.
…oops.
After doing any action, the interface does not react.
Why? Well, we didn’t implement any
means of synchronization. After adding a place using the imported method, then we’re not signalled about it
anywhere. We can’t even put the getPlaces() method in the next line after invoking addPlace(), because city lookup is asynchronous and takes
time to accomplish.
Things are happening in the background, but our interface is not aware of its results — after adding a marker on the map, we’re not seeing the change in the sidebar. How to solve it?
A pretty simple idea is to poll our service once in a while — for instance, every component could get items from the service every second. E.g.:
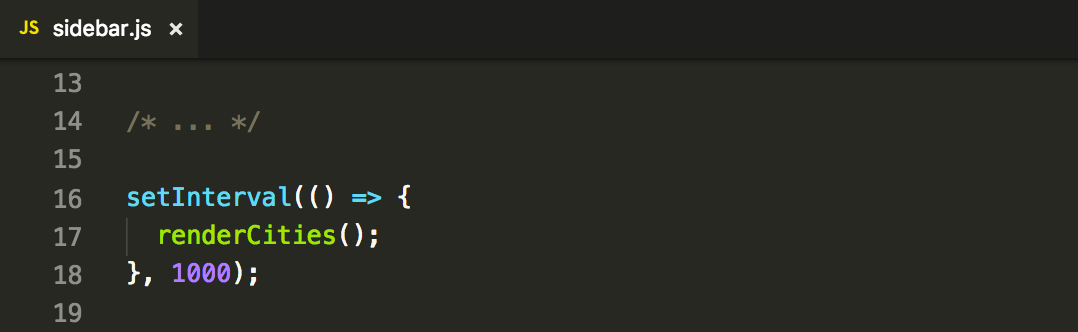
Does it work? Choppy, but yes. But is it optimal? Not at all — we’re flooding event loop of our app with actions that won’t have any effect in the majority of cases.
After all, you’re not visiting your local post office every hour to check if the package has arrived. Similarly, if you’re leaving our car for repairs, you don’t call the mechanic every half hour to ask if the job is done (at least hopefully you’re not this kind of person). Instead, we’re waiting for a phone call. And when the job is ready, how does the mechanic know who to call? Silly — of course, we have left him our contact data.
Now, let’s try to mimic “leaving our contact data” in the JavaScript.
JavaScript is very fancy language —
one of its quirky characteristics is treating functions as any other values. Using formal description,
“functions are first-class citizens”. It means that any function can be assigned to a variable or passed as
a parameter to another function. You already know this mechanism: remember,setTimeoutsetInterval and various event listener callbacks? They work by
consuming functions as parameters.
This characteristic is fundamental in asynchronous scenarios.
We can define a function that would update our UI — and then pass it to completely another portion of the code, where it will be called.
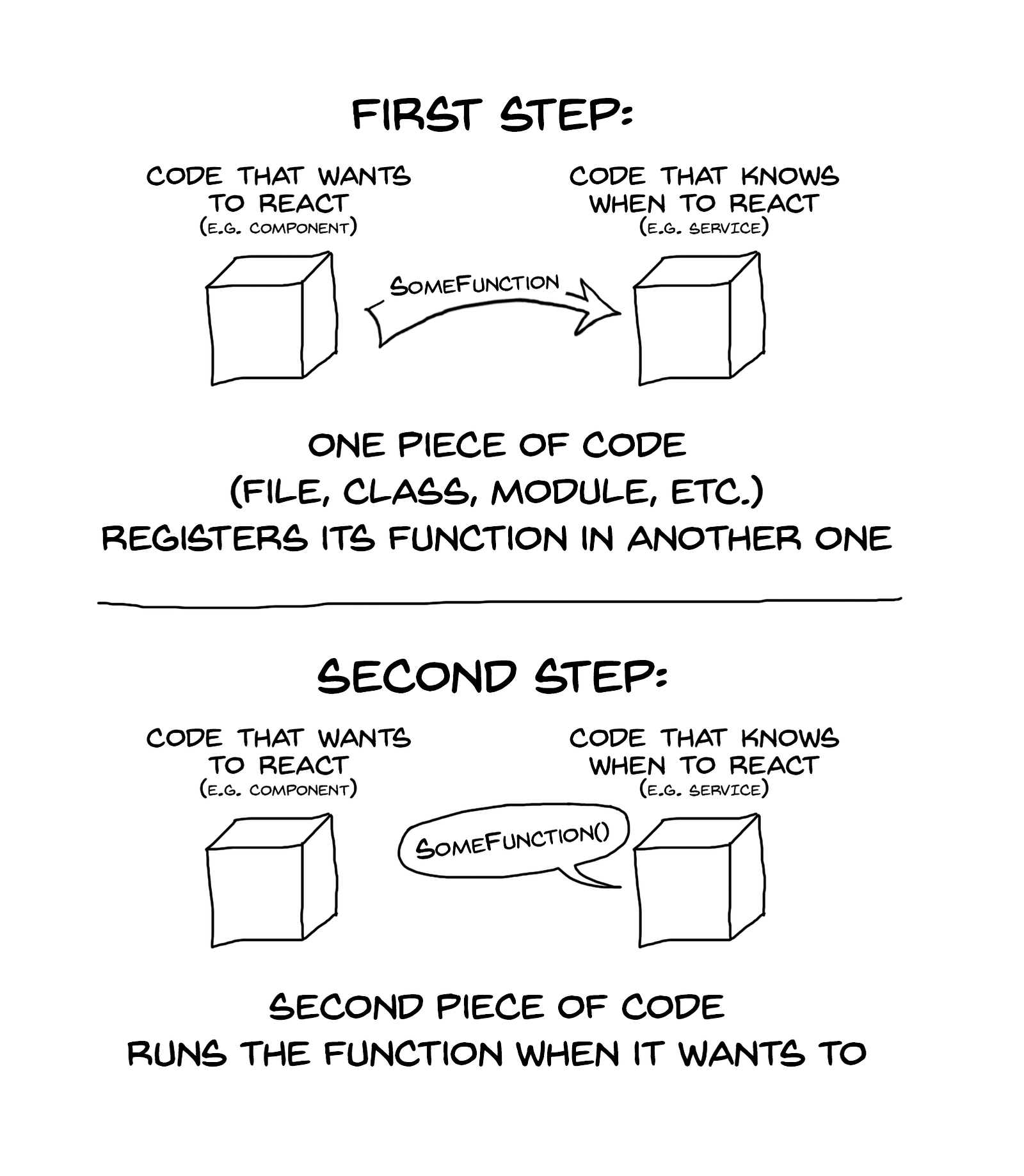
Using this mechanism, we can take
our renderCities and somehow pass it to the dataService. There, it will be invoked when necessary:
after all, the service knows precisely when data should be transferred to components — not the other
way.
Let’s try! We will start with adding a capability of remembering the function on the service side, then invoking it in the certain moment.
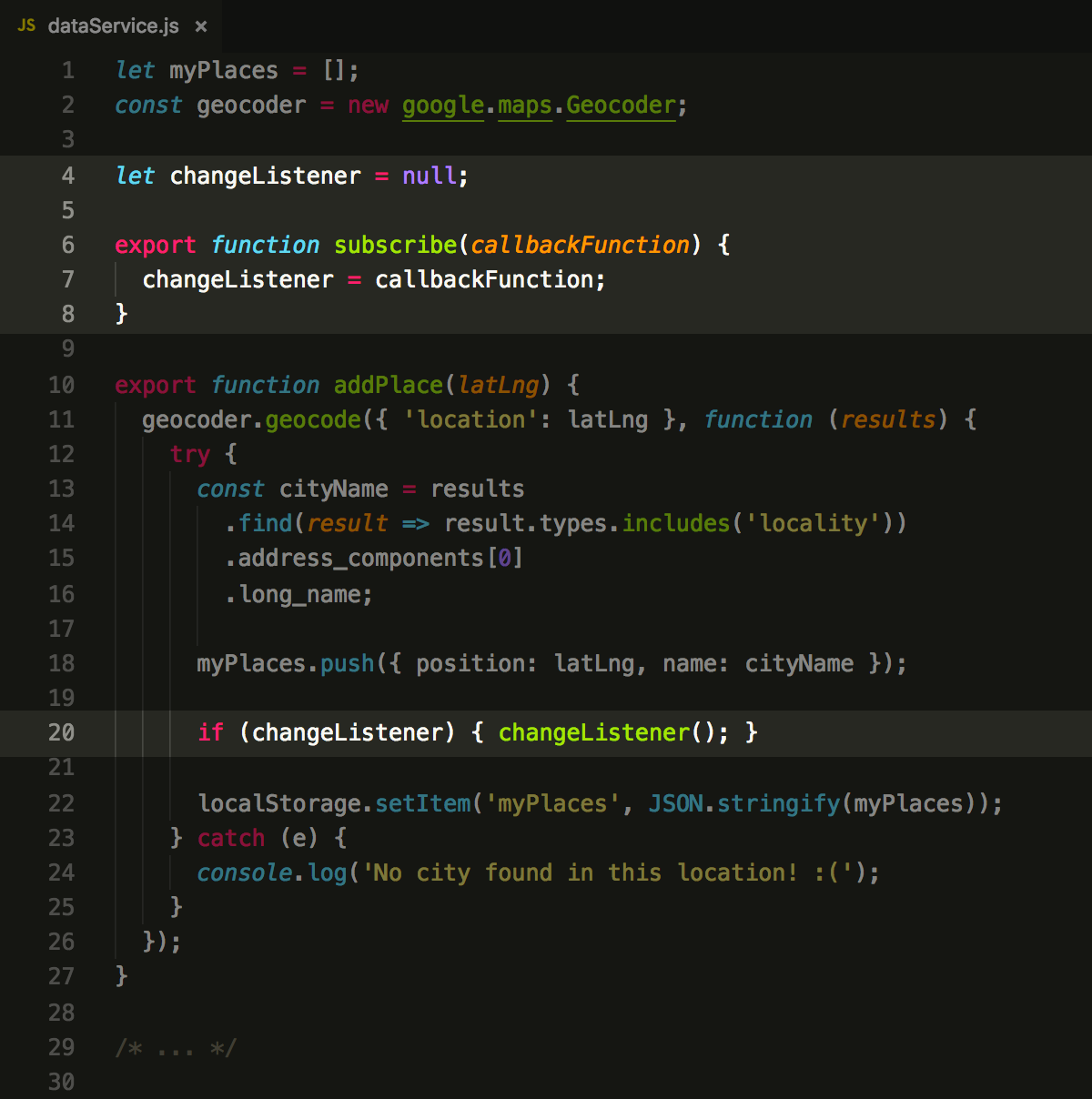
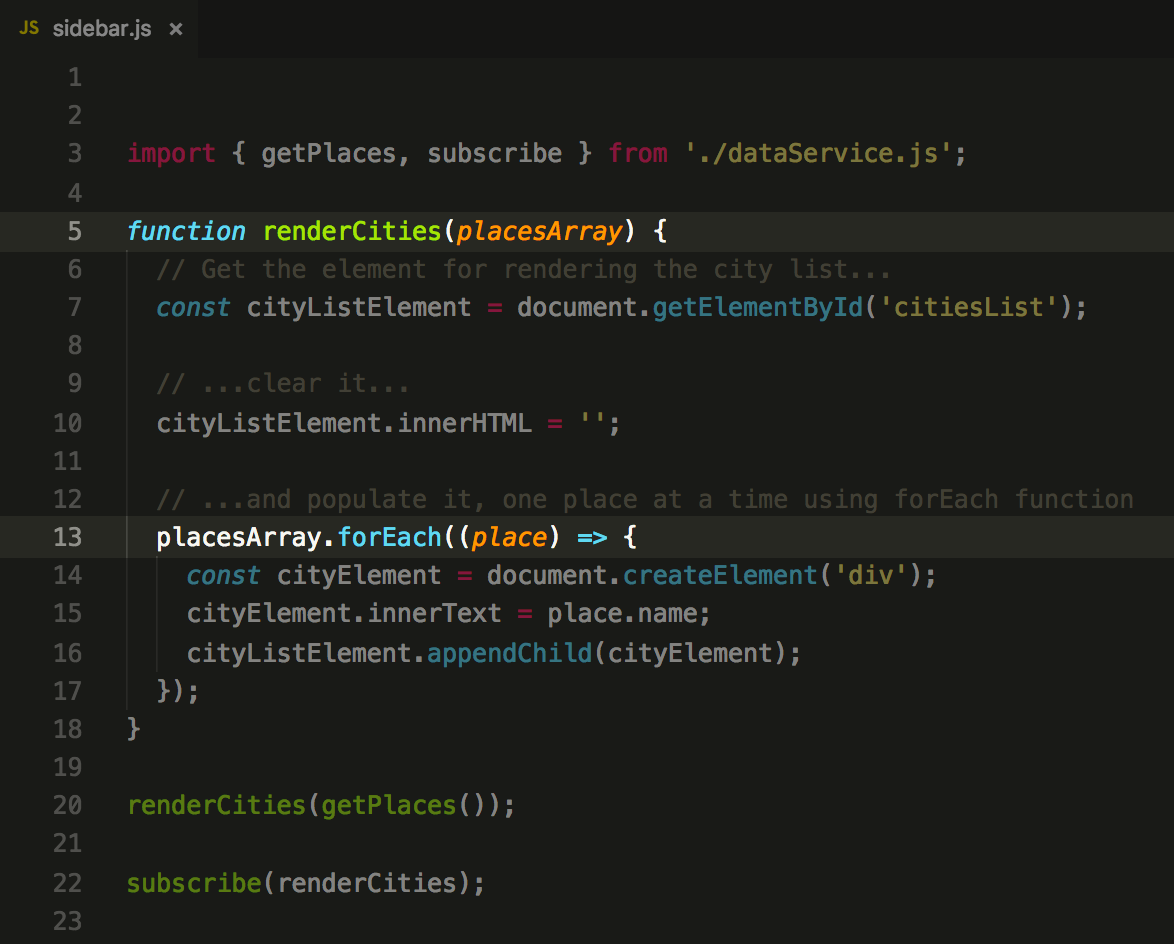
Now, let’s attach it to the sidebar:
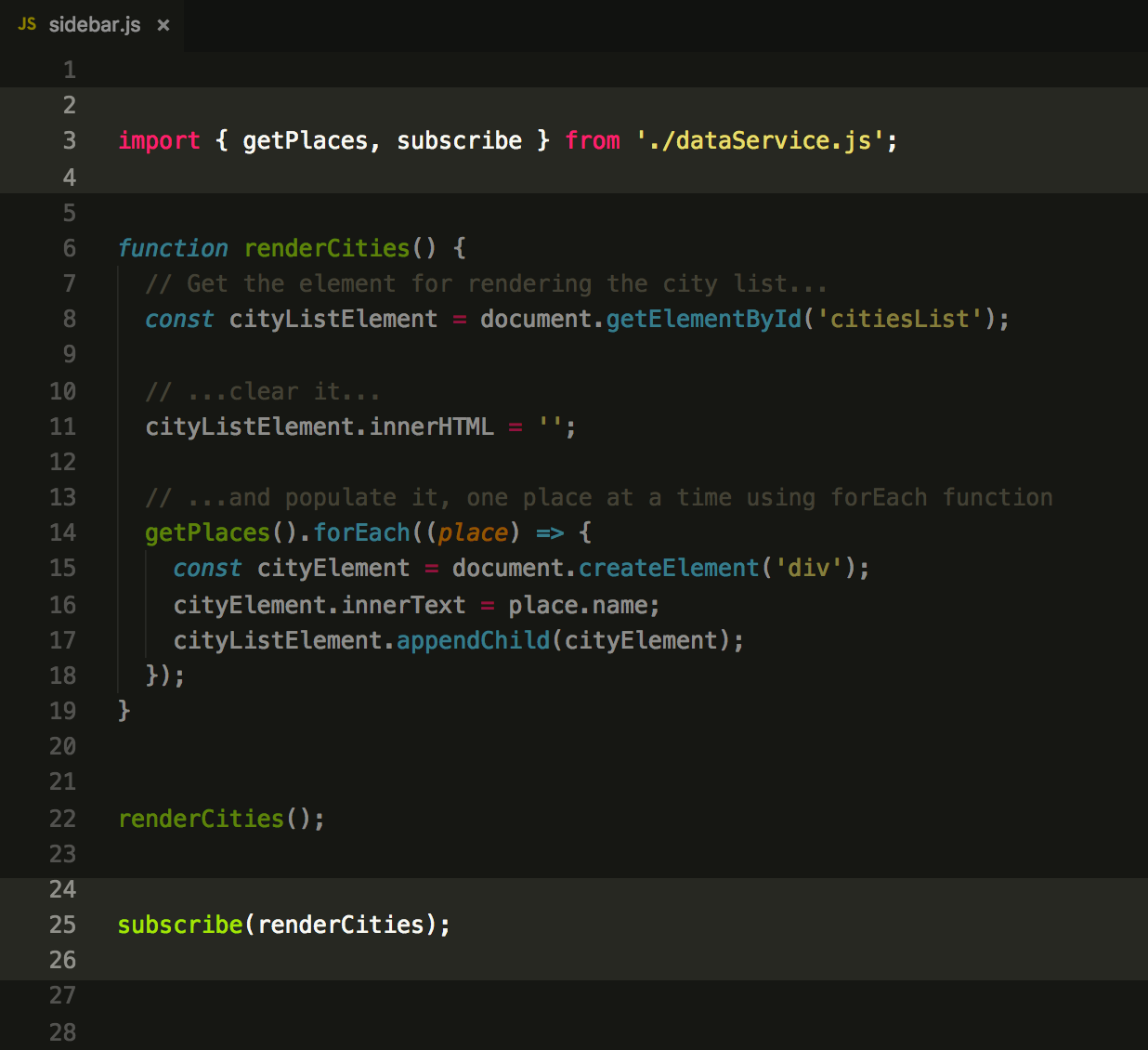
Do you see what’s happening here?
While our sidebar code is being loaded, it registers renderCities function
inside the dataService.
Then, dataService invokes this
function when it needs to — in this case, when our data changes (due
to addPlace() invocation).
In exact: one part of our code is SUBSCRIBER of the event (sidebar component), another part is PUBLISHER (service method). Boom, we have implemented the most basic form of the publish-subscribe pattern, which is a fundamental concept for nearly all advanced asynchronous concepts.
What’s more to it?
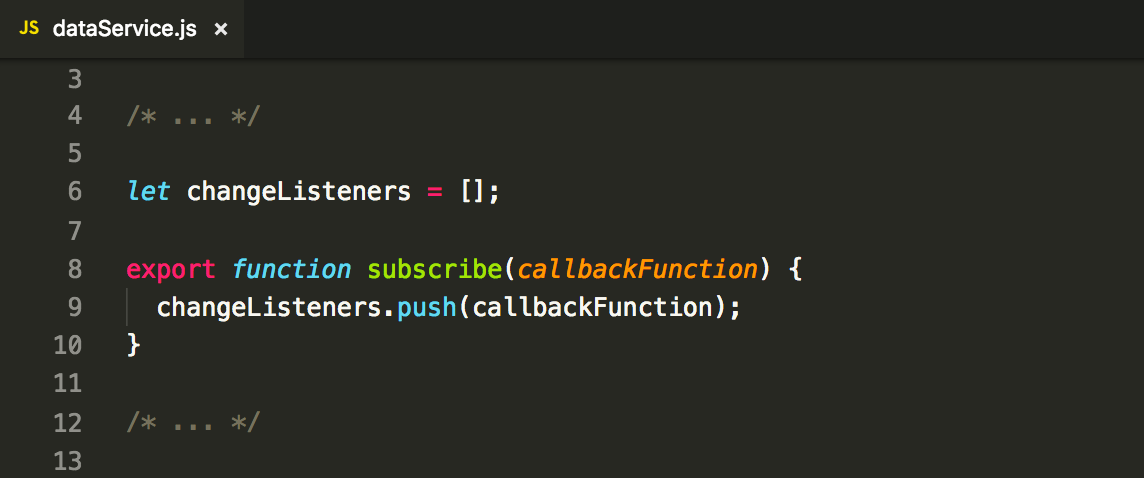
Note that using this code, we have
limited ourselves to only one listening component (or in other words, to only one subscriber). If any other
function will be passed using subscribe() function, it will overwrite current changeListener there. To deal with this, we can set
up a whole array of listeners:
Now, we can tidy up the code a little and write a function that will invoke all the listeners for us:
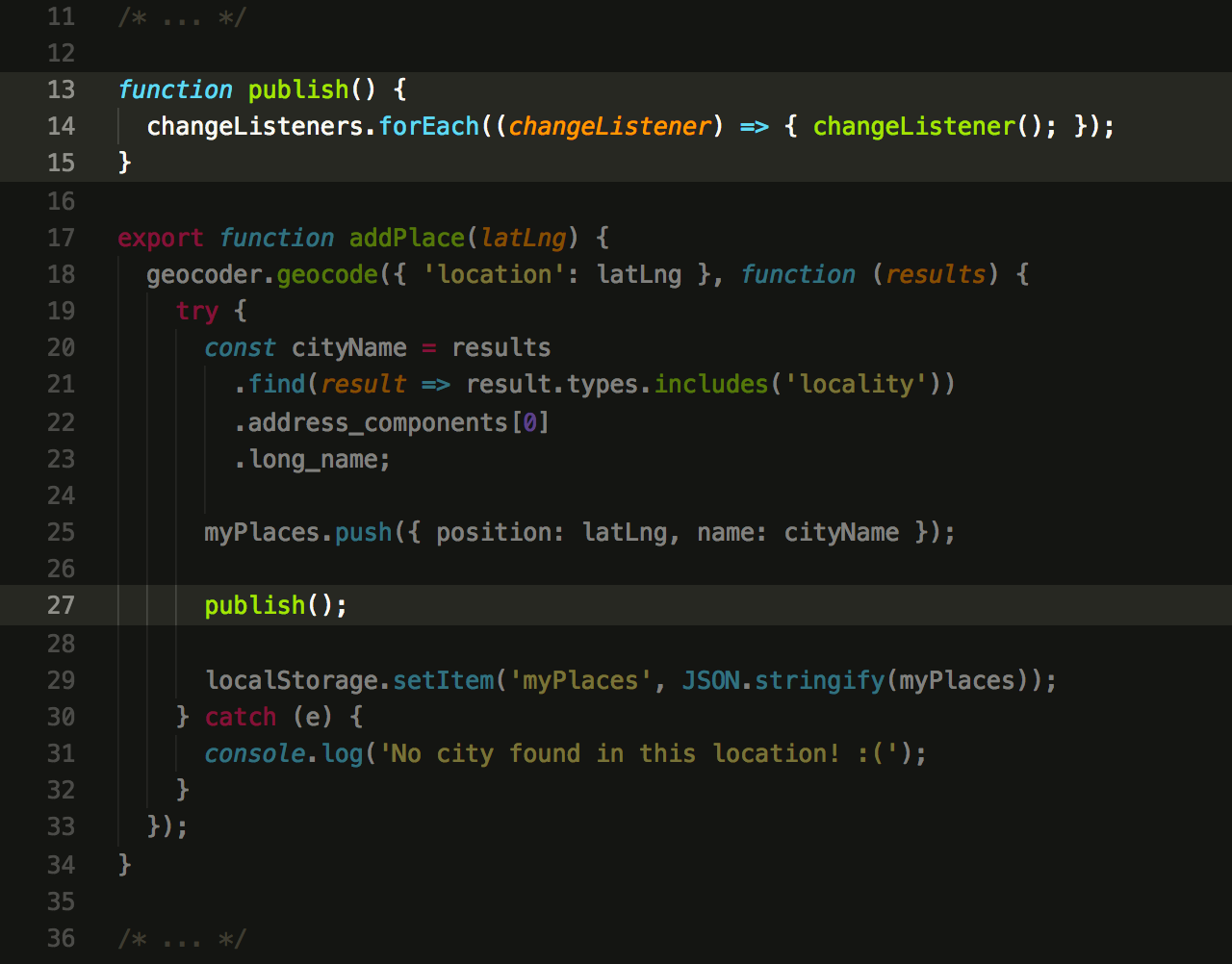
This way we can also wire up
the map.js component so it will react properly for all actions in the service:
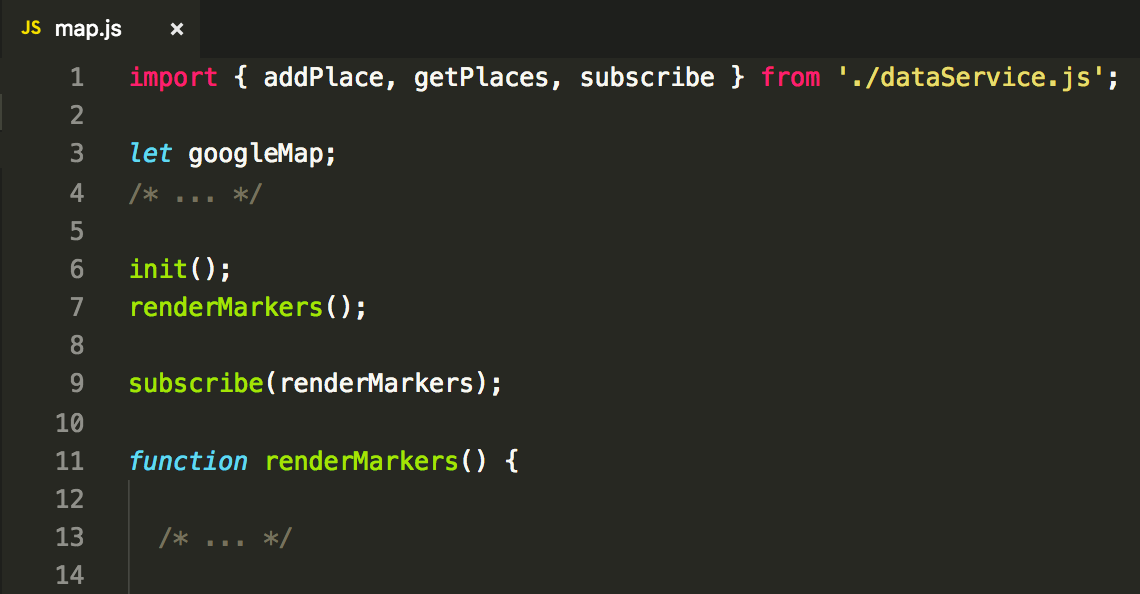
What about using subscribers as a method of transporting the data? This way, we can get markers straight using a parameter of a listener. Like this:
Then, it’s possible to easily retrieve the data back in the component:
There are many more possibilities
here — we can create different topics (or channels) for different kinds of actions. Also, we could
extract publish and subscribe methods to completely separate code file and use it from there. But for now,
we’re good — below is a short video of an app using the very same code that we have just created:
Does this whole publish-subscribe thing resemble something you might already know? After giving it some thought,
it’s the pretty same mechanism that you use in element.addEventListener(action, callback). Subscribe your
function to a particular event, which is being called when some action
is published by element. Same story.
Going back to the title: why is this thing so bloody important? After all, in the long run, there is little sense in holding up to vanilla JavaScript and modifying the DOM manually — same goes with manual mechanisms for passing and receiving events. Various frameworks have their established solutions: Angular uses RxJS, React have state and props management with the possibility of boosting it with Redux, literally every usable framework or library have its own method of data synchronization.
Well, the truth is that all of them use some variation of the publish-subscribe pattern.
As we already said — DOM event
listeners are nothing more than subscribing
to publishing UI actions. Going further: what is a Promise? From a certain point of view, it’s just a
mechanism that allows us to subscribe for completion of a certain deferred
action, then publishes some data when ready.
React state and props change?
Components’ updating mechanisms are subscribed to the changes.
Websocket’s on()?
Fetch API? They allow to subscribe to certain network action. Redux? It allows
to subscribe to changes in the store. And RxJS? It’s a shameless one
big subscribe pattern.
It’s the same principle. There are no magic unicorns under the hood. It’s just like the ending of the Scooby-Doo episode.
It’s not a great discovery. But it’s important to know:
No matter what method of solving asynchronous problem will you use, it will be always some variation of the same principle: something subscribes, something publishes.
That’s why it is so essential. You can always think of publish and subscribe. Take note and keep going. Keep building larger and more complex application with many asynchronous mechanisms — and no matter how difficult it may look like, try to synchronize everything with publishers and subscribers.
Still, there is a number of topics untouched in this story:
- Mechanisms of unsubscribing listeners when not needed anymore,
- Multi-topic subscribing (just like
addEventListenerallows you to subscribe to different events), - Expanded ideas: event buses, etc.
To expand your knowledge, you can review a number of JavaScript libraries that implement publish-subscribe in its bare form:
Go ahead and try to use them, break them and run the debugger in order to see what happens under the hood. Also, there is a number of great articles that describe this idea very well.
You can find the code from this story in the following GitHub repository:
Keep experimenting and tinkering — and don’t be afraid of the buzzwords, they’re usually just regular code in disguise.
Keep thinking. See you!


